What Should a Blockchain Remember in Federated Learning?
One of the most common instincts in decentralized learning is also one of the least disciplined ones: if the parameter server is the bottleneck, then perhaps the blockchain should remember everything.
That instinct sounds principled, but it quietly overloads the chain with the wrong job. A ledger is very good at keeping a small amount of high-value state that many parties need to trust. It is much less good at being a dump for every intermediate artifact in a learning loop. What I still find compelling in FAIR-BFL is that it asks a sharper question: what is the minimum state that the blockchain really needs to remember if the goal is trustworthy federated learning, rather than blockchain theater?
Why this paper still matters
It treats fairness as a systems primitive. The same quantity that decides who gets rewarded also decides whose gradients should shape the next global model.
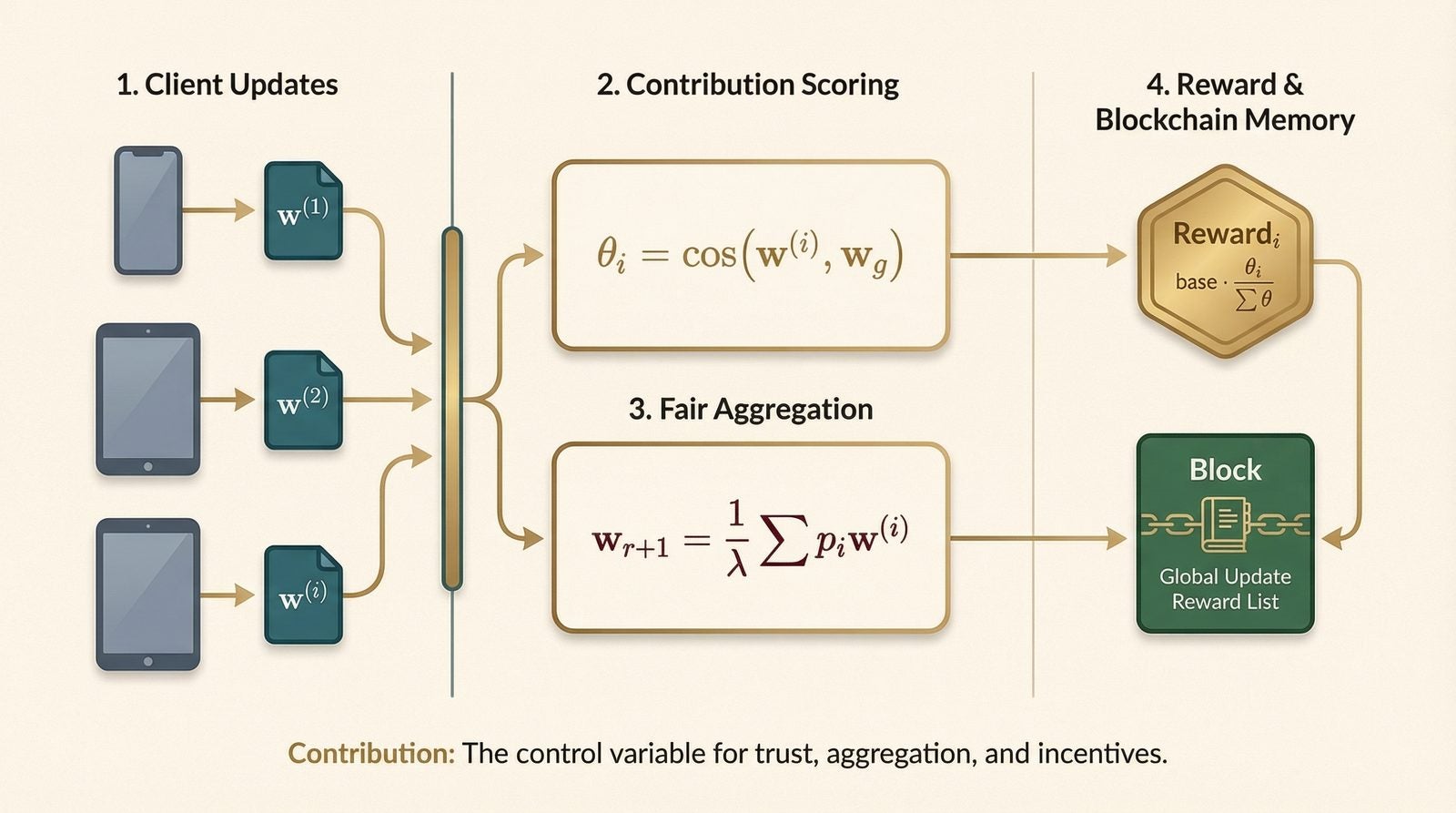
Instead of asking the chain to store everything, FAIR-BFL turns contribution into the main control variable and stores only the state that changes trust.
The wrong question is “How do we remove the server?”
Removing the server is not enough. Vanilla blockchain-based federated learning can still be naive in at least three ways:
- the chain and the learning loop are only loosely coupled;
- too much round-level information is pushed on-chain;
- incentives are based on mining success or self-reported effort rather than learning value.
The interesting move in FAIR-BFL is to say that these are not separate annoyances. They are all symptoms of one design mistake: contribution is missing as a first-class object.
Contribution should come from model behavior, not attendance
The paper uses the geometry of updates to score how much a client actually matters to the round. That idea is easy to miss if one reads the paper only as “blockchain plus FL.” In practice it means the system stops rewarding clients merely for showing up. It starts rewarding them for how much their update aligns with the evolving global model.
Fair aggregation
$$w_{r+1} \leftarrow \frac{1}{\lambda}\sum_{i=1}^{n} p_i w_{r+1}^{i}, \qquad p_i = \frac{\theta_i}{\sum_{k=1}^{\lambda n}\theta_k}.$$
Contribution-based reward
$$\mathrm{reward}_i = \mathrm{base}\cdot\frac{\theta_i}{\sum_{k=1}^{\lambda n}\theta_k}, \qquad \theta_i = \operatorname{CosineDistance}(w_{r+1}^{i}, w_{r+1}).$$
What I like about these equations is not their complexity. It is their economy. One score, theta_i, now touches aggregation, incentives, and robustness at once. That is a stronger systems idea than many papers that advertise a longer feature list.
Fairness is also an optimization trick
There is a pleasant inversion here. “Fairness” sounds like a moral or institutional layer that comes after optimization. FAIR-BFL suggests the reverse: if low-value or suspicious updates are allowed to shape the global model with the same force as high-value ones, the optimizer itself becomes less stable. The paper’s discard strategy is therefore not just an economic filter. It is also a noise filter.
That is why the paper’s empirical story is interesting even without reading every table. The point is not merely that some clients get lower rewards. The deeper point is that once low-contributing clients are de-emphasized, the system can become both faster and more accurate, because the pipeline stops paying full price for low-quality gradients.
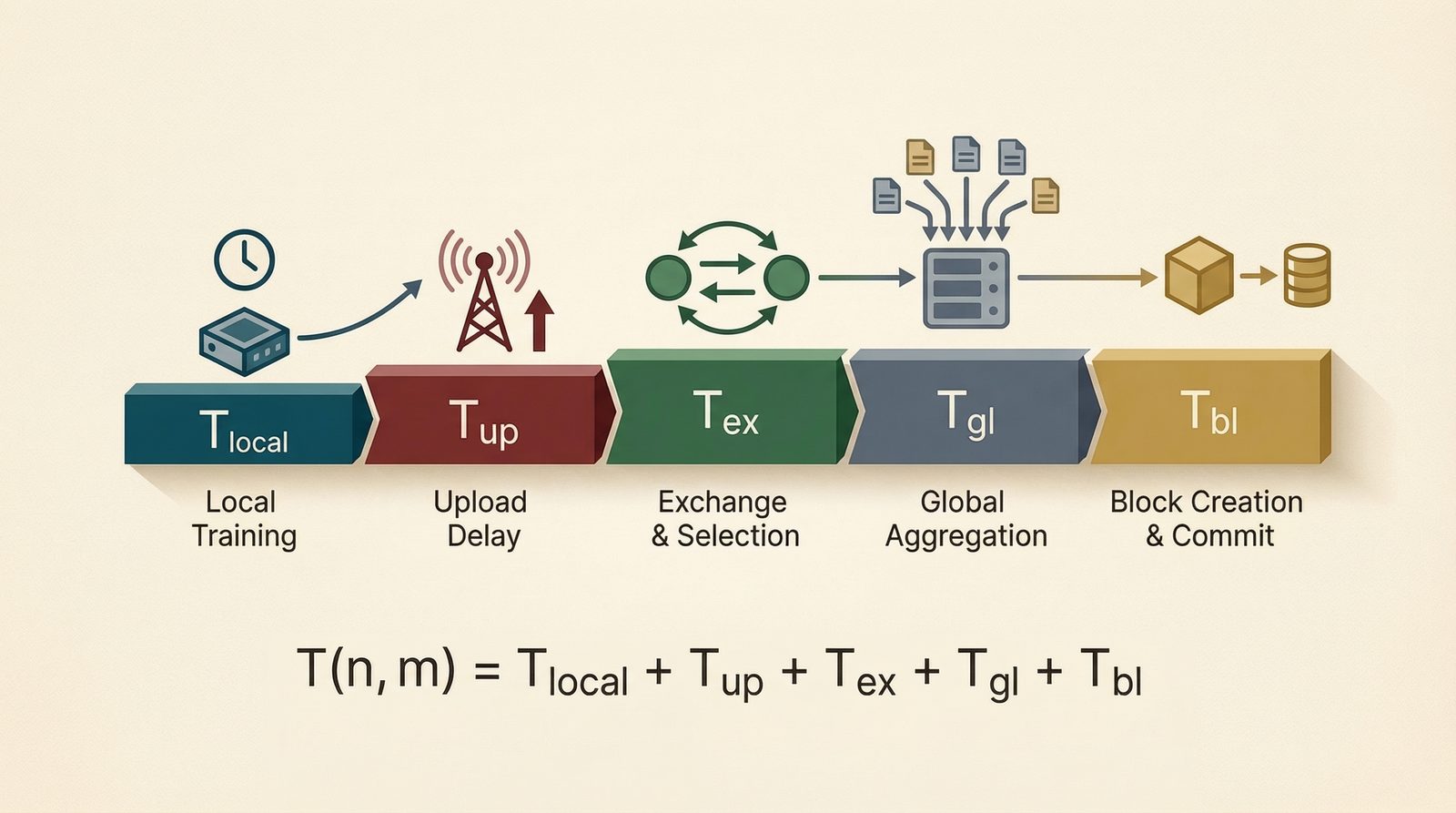
The coordination stack matters. The paper models total delay as a sum of local training, upload, exchange, aggregation, and block commitment.
Delay as a pipeline
$$T_{(n,m)} = T_{\mathrm{local}} + T_{\mathrm{up}} + T_{\mathrm{ex}} + T_{\mathrm{gl}} + T_{\mathrm{bl}}.$$
Once written this way, the blockchain stops looking like a magical replacement for coordination and starts looking like one stage in a larger systems pipeline. That framing is healthy. It pushes us to ask what deserves scarce trust bandwidth, and what should stay off-chain.
What I would push further today
If I were extending this line of work now, I would push on three fronts.
- Richer contribution signals. Cosine geometry is a disciplined start, but modern collaborative systems can also ask whether an update improves robustness, calibration, or downstream task fit.
- Strategic behavior. The moment rewards depend on contribution, agents have incentives to look useful rather than be useful. That creates a mechanism-design layer beyond classic poisoning defenses.
- Memory budgets. The paper already asks the right on-chain question. In larger AI systems, the next step is to decide which summaries, proofs, or audit trails deserve persistent storage.
The broad lesson I take from FAIR-BFL is simple: decentralized learning does not become trustworthy because it is decentralized. It becomes more trustworthy when the system has a disciplined answer to two questions: whose update counts, and what exactly should everyone remember?
Primary sources: arXiv, ICPP 2022 DOI.